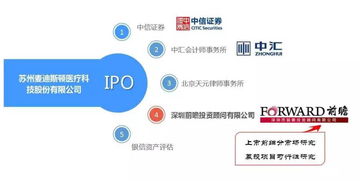
在醫療行業,回扣、關系營銷等潛規則長期被視為難以撼動的“慣例”。蘇州麥迪斯頓醫療科技股份有限公司(以下簡稱“麥迪斯頓”)卻以其獨特的商業模式和發展路徑,成功打破了這一固有認知。公司堅守“不行賄、不作惡”的底線,專注于以科技創新和專業化服務構建核心競爭力,并最終使其首次公開募股(IPO)申請獲得通過。這一切,與其深度依托并創新的“科技中介服務”模式密不可分。
一、 堅守底線:在“灰色地帶”中開辟清白航道
醫療設備及信息化市場,尤其是公立醫院采購領域,傳統上被認為是關系密集型行業。麥迪斯頓自成立之初,便明確將合規與誠信置于企業文化的核心。創始人及管理團隊堅信,企業的長遠發展必須建立在真實價值創造之上,而非短期利益交換。
這種“不行賄”的承諾,并非一句空洞的口號。它意味著公司在市場拓展、客戶維護上,必須付出更高的成本和更艱辛的努力。麥迪斯頓的選擇是:將全部精力投入到產品研發、技術升級與服務質量上。通過提供真正能解決臨床痛點、提升醫院管理效率的麻醉、重癥監護等圍手術期臨床信息系統,以及數字化手術室整體解決方案,用硬實力而非“潛規則”去贏得客戶的信任和訂單。這種堅持,雖然前期可能步履維艱,卻為公司建立了極其珍貴的品牌聲譽和干凈的商業記錄,這恰恰是走向公開資本市場時最堅實的基石。
二、 核心引擎:科技中介服務的深度實踐與升級
“科技中介服務”是理解麥迪斯頓商業模式的關鍵。它并非簡單的“中間商”或“代理”,而是一個以技術為橋梁,深度融合醫療需求與先進解決方案的價值創造平臺。麥迪斯頓的實踐主要體現在三個層面:
- 技術整合與創新中介:公司扮演了將國際先進醫療設備技術、信息技術與國內醫療機構具體需求進行對接、本地化和再創新的角色。它不僅僅是銷售產品,更是提供一套融合了硬件、軟件和臨床知識的智能化整體解決方案。例如,其核心產品麻醉臨床信息系統,就是深度理解麻醉科工作流程后,通過信息技術進行優化和管理的典范。
- 服務增值與知識中介:麥迪斯頓提供了遠超傳統設備供應商的持續服務。包括系統的安裝、調試、培訓、維護、升級以及基于數據的運營分析建議。這種深度服務使其與醫院客戶從“一次性買賣關系”轉變為長期的、基于共同提升醫療質量的“合作伙伴關系”。公司充當了醫療IT知識和最佳實踐傳播的“中介”,幫助醫院提升整體數字化水平。
- 生態構建與資源中介:隨著業務發展,麥迪斯頓逐漸構建起一個連接醫療器械廠商、軟件開發商、醫院、專家乃至患者的微小生態。它通過自身的平臺,高效匹配和調動生態內的技術、數據與需求資源,從而創造出更大的協同價值。
這種“科技中介服務”模式,使得麥迪斯頓的盈利來源變得多元化且更具粘性,從單純的產品銷售延伸到高毛利的軟件授權、技術服務、系統升級和運營維護,形成了可持續的良性收入結構。
三、 資本認可:合規價值與科技含金量贏得IPO通行證
麥迪斯頓IPO首發獲通過,是市場對其發展模式的高度肯定。在嚴格的上市審核中,公司的“清白”背景和清晰的盈利模式成為巨大優勢。
- 財務透明與合規性:堅持合規經營確保了財務數據的真實、清晰,沒有因“潛規則”帶來的隱蔽支出或法律風險,這極大地降低了監管審核的顧慮。
- 核心技術護城河:持續的研發投入,積累了大量自主知識產權和核心技術。其軟件產品的高標準化和可復制性,帶來了良好的規模效應和盈利能力,這正是科技型企業的魅力所在。
- 商業模式可持續性:基于“科技中介服務”的長期服務模式,產生了穩定的經常性收入,業務增長可預測性強,展示了良好的發展前景。
- 行業趨勢順應者:在國家大力推行醫療信息化、智慧醫院建設及醫療器械國產化替代的政策東風下,麥迪斯頓的主營業務正處于黃金賽道,其堅持技術創新和價值服務的理念與政策導向高度契合。
四、 啟示與展望:正道亦可成坦途
麥迪斯頓的成功案例向醫療科技行業乃至所有存在“潛規則”的領域昭示:依靠技術創新和專業服務構建的“硬實力”,完全可以超越依靠灰色手段的“軟關系”。在監管日益嚴格、市場日趨規范、價值回歸本質的大環境下,“不行賄、不作惡”不僅是一種道德選擇,更是一種明智的商業戰略。
其“科技中介服務”的深化,未來可能進一步向醫療大數據分析、人工智能輔助診斷、區域醫療協同等方向拓展,其平臺價值將愈發凸顯。麥迪斯頓的上市,不僅是一次資本的跨越,更是對其所秉持的“清流”商業價值觀的一次勝利驗證,為行業樹立了一個值得借鑒的標桿:在陽光下盈利,道路同樣可以通往羅馬。