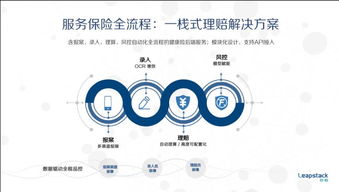
在保險(xiǎn)行業(yè)數(shù)字化轉(zhuǎn)型浪潮中,保險(xiǎn)中介作為連接保險(xiǎn)公司與消費(fèi)者的重要橋梁,其服務(wù)能力與效率直接影響著市場(chǎng)體驗(yàn)與行業(yè)生態(tài)。以棧略數(shù)據(jù)為代表的科技中介服務(wù)機(jī)構(gòu),正通過技術(shù)創(chuàng)新,特別是聚焦于理賠環(huán)節(jié)的深度整合與優(yōu)化,助力傳統(tǒng)保險(xiǎn)中介構(gòu)建覆蓋投保、核保、理賠、風(fēng)控等環(huán)節(jié)的全流程、智能化服務(wù)能力,從而在激烈的市場(chǎng)競(jìng)爭中塑造核心優(yōu)勢(shì)。
一、傳統(tǒng)保險(xiǎn)中介的痛點(diǎn)與挑戰(zhàn)
傳統(tǒng)保險(xiǎn)中介業(yè)務(wù)長期面臨服務(wù)鏈條割裂、運(yùn)營效率低下、信息不對(duì)稱等諸多挑戰(zhàn)。尤其在理賠環(huán)節(jié),流程繁瑣、周期冗長、材料審核依賴人工、欺詐風(fēng)險(xiǎn)難控等問題突出,不僅消耗大量人力物力,更直接影響客戶滿意度與信任度。隨著消費(fèi)者對(duì)便捷、透明、高效服務(wù)的需求日益增長,以及保險(xiǎn)產(chǎn)品復(fù)雜度的提升,單純依賴人力與經(jīng)驗(yàn)的傳統(tǒng)服務(wù)模式已難以為繼。保險(xiǎn)中介亟待通過技術(shù)手段重塑服務(wù)流程,而理賠作為保險(xiǎn)服務(wù)價(jià)值的最終體現(xiàn),自然成為轉(zhuǎn)型的關(guān)鍵突破口。
二、科技賦能:以理賠整合驅(qū)動(dòng)全流程升級(jí)
棧略數(shù)據(jù)等科技服務(wù)商,運(yùn)用大數(shù)據(jù)、人工智能、規(guī)則引擎、知識(shí)圖譜等技術(shù),為保險(xiǎn)中介提供了系統(tǒng)性解決方案。其核心在于將理賠環(huán)節(jié)從傳統(tǒng)的“事后處理”節(jié)點(diǎn),轉(zhuǎn)變?yōu)轵?qū)動(dòng)前端服務(wù)優(yōu)化與后端風(fēng)控強(qiáng)化的數(shù)據(jù)中樞與價(jià)值樞紐。
- 智能化理賠處理:通過OCR、NLP技術(shù)自動(dòng)識(shí)別和解析醫(yī)療票據(jù)、診斷證明等理賠材料,結(jié)合規(guī)則引擎自動(dòng)進(jìn)行責(zé)任判定與理算,大幅縮短處理時(shí)間,降低人工成本與差錯(cuò)率。智能化的案件分配與狀態(tài)跟蹤,也提升了流程透明度與客戶溝通效率。
- 全流程風(fēng)控嵌入:理賠數(shù)據(jù)是識(shí)別欺詐行為、評(píng)估風(fēng)險(xiǎn)規(guī)律的關(guān)鍵。科技平臺(tái)通過構(gòu)建反欺詐模型、醫(yī)療知識(shí)圖譜等,能夠在理賠申請(qǐng)時(shí)實(shí)時(shí)進(jìn)行風(fēng)險(xiǎn)篩查與提示,并將風(fēng)險(xiǎn)洞察反饋至核保、產(chǎn)品設(shè)計(jì)等前端環(huán)節(jié),形成“核保-理賠”一體化的動(dòng)態(tài)風(fēng)控閉環(huán),幫助中介機(jī)構(gòu)有效控制賠付成本。
- 數(shù)據(jù)驅(qū)動(dòng)的服務(wù)延伸:整合后的理賠數(shù)據(jù)池,成為分析客戶健康狀況、服務(wù)需求、產(chǎn)品適配度的寶貴資源。中介機(jī)構(gòu)可據(jù)此為客戶提供個(gè)性化的健康管理建議、保單檢視、產(chǎn)品優(yōu)化方案等增值服務(wù),推動(dòng)角色從“銷售渠道”向“風(fēng)險(xiǎn)管理與健康服務(wù)伙伴”轉(zhuǎn)型,增強(qiáng)客戶粘性與終身價(jià)值。
- 生態(tài)連接與協(xié)同:科技平臺(tái)可幫助中介機(jī)構(gòu)高效連接醫(yī)院、藥企、健康管理機(jī)構(gòu)、保險(xiǎn)公司等多方,實(shí)現(xiàn)數(shù)據(jù)與服務(wù)的合規(guī)、安全流轉(zhuǎn)與協(xié)同。例如,直連醫(yī)院系統(tǒng)獲取結(jié)構(gòu)化診療數(shù)據(jù),可極大簡化理賠材料提交流程,提升服務(wù)體驗(yàn)。
三、構(gòu)建面向未來的科技中介服務(wù)能力
對(duì)于保險(xiǎn)中介而言,借助棧略數(shù)據(jù)這樣的科技伙伴整合理賠并提升全流程服務(wù)能力,不僅是效率工具的應(yīng)用,更是一次深度的業(yè)務(wù)模式重構(gòu)。它要求中介機(jī)構(gòu):
- 確立科技戰(zhàn)略核心地位:將科技投入視為提升長期競(jìng)爭力的關(guān)鍵,積極擁抱數(shù)據(jù)驅(qū)動(dòng)決策的文化。
- 注重?cái)?shù)據(jù)資產(chǎn)積累與治理:在合法合規(guī)前提下,有序積累、清洗、分析業(yè)務(wù)數(shù)據(jù),尤其是理賠相關(guān)數(shù)據(jù),使其成為可挖掘的資產(chǎn)。
- 推動(dòng)組織與流程適配:調(diào)整內(nèi)部組織架構(gòu)與作業(yè)流程,使之與智能化系統(tǒng)高效協(xié)同,培養(yǎng)兼具保險(xiǎn)知識(shí)與科技素養(yǎng)的復(fù)合型人才。
- 深化以客戶為中心的服務(wù)理念:利用科技手段將服務(wù)觸點(diǎn)貫穿客戶全生命周期,提供無縫、貼心、專業(yè)的體驗(yàn)。
結(jié)語
在“保險(xiǎn)+科技”深度融合的時(shí)代,理賠不再只是成本中心和糾紛源頭,而是保險(xiǎn)中介提升服務(wù)品質(zhì)、優(yōu)化風(fēng)險(xiǎn)定價(jià)、開拓價(jià)值增長的新引擎。棧略數(shù)據(jù)等科技中介服務(wù)商通過賦能理賠環(huán)節(jié)的智能化、整合化,正助力保險(xiǎn)中介打破服務(wù)壁壘,構(gòu)建從前端咨詢到后端理賠、從風(fēng)險(xiǎn)防范到健康管理的全方位、數(shù)字化服務(wù)能力。這不僅是行業(yè)降本增效的必然路徑,更是保險(xiǎn)中介在日益復(fù)雜的市場(chǎng)環(huán)境中贏得客戶、實(shí)現(xiàn)可持續(xù)發(fā)展的戰(zhàn)略選擇。持續(xù)深化科技應(yīng)用、構(gòu)建開放共贏的生態(tài)服務(wù)體系,將是保險(xiǎn)中介轉(zhuǎn)型升級(jí)的主旋律。









